



表列(例如存储名字的列)可能有许多重复值。如果你想列出不同的(非重复)值,则需要一种无需编写复杂的 SQL 语句就能做到的方法。在 ANSI SQL 兼容的数据库(如 PostgreSQL、SQL Server 和 MySQL)中,从列中选择非重复值的方法是使用 SQL DISTINCT 子句。它会从 SELECT 语句的结果集中删除重复项,只留下唯一值。在这篇文章中,我们将学习如何使用它。
语法和行为
若要使用 SQL DISTINCT 子句,你需要在 SELECT 和列和/或表达式列表之间加入 DISTINCT 关键字,如下所示:
SELECT DISTINCT columns/expressions FROM tables [WHERE conditions];
你可以在语句中包含一个或多个列和/或表达式,因为查询会用 SELECT 列表中所有指定列的值组合来评估它们的唯一性。此外,如果将 DISTINCT 子句应用于具有 NULL 值的列,DISTINCT 子句就会仅保留一个 NULL 并消除其他 NULL。换句话说,DISTINCT 子句将所有 NULL 值视为相同的值。
单一个列的示例
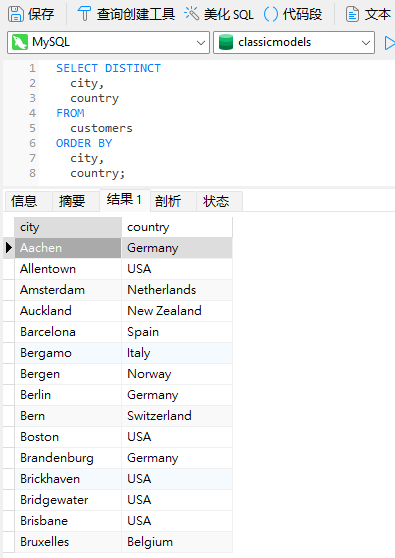
查询的一个常见用途是列出公司客户或用户的所有城市和/或国家/地区。以下是在Navicat Premium 16 中针对 classicmodels 示例数据库编写的查询:
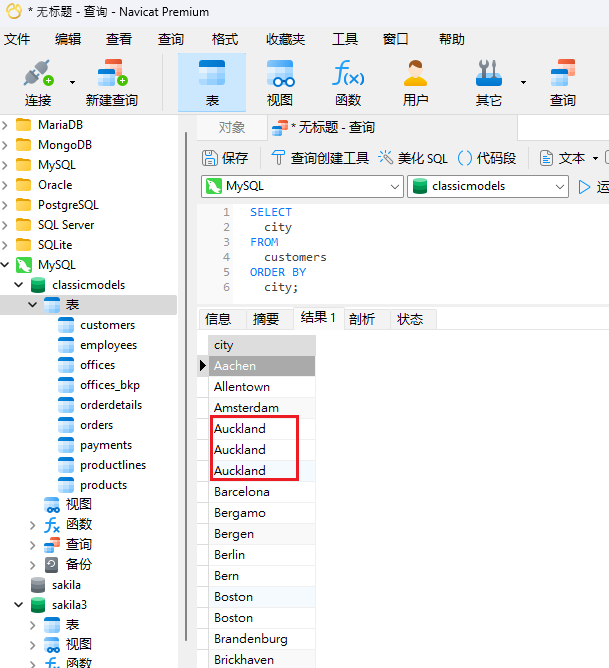
如红色框所示,名单中有重复的城市。
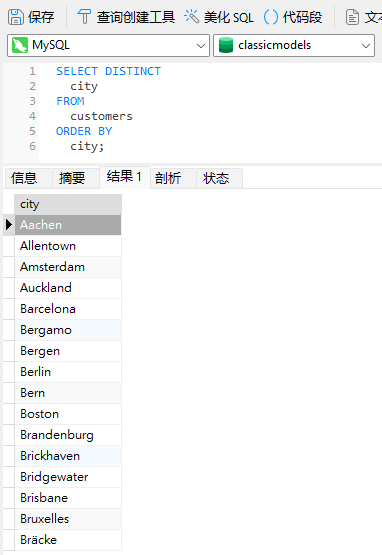
若要获得一个没有重复的城市名单,我们可以将 DISTINCT 关键字加到 SELECT 语句中:
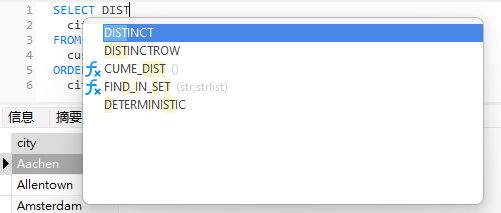
我我们可以利用 Navicat 的代码补全功能来弹出 DISTINCT 关键字。当你在编辑器中输入 SQL 语句时,Navicat 会在下拉列表中显示信息,它会帮助你完成编写语句和显示数据库对象的可用属性(例如数据库、表、字段、视图等)及其相应的图标:
多个列的示例
DISTINCT 关键字也可以应用于多个列。在这种情况下,查询将只返回所有选定列都是唯一的行。首先,让我们将 country 字段加到我们的最后一个查询中:
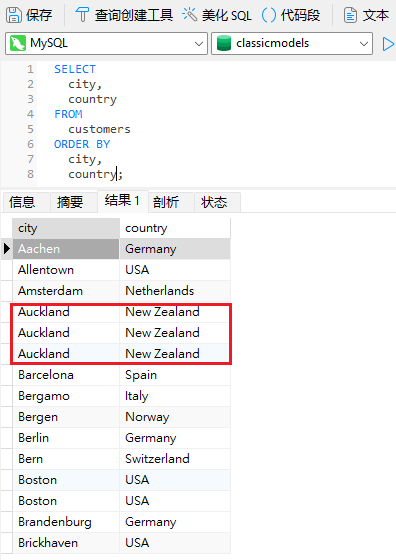
我们又一次看到了重复项,因为重复的城市很可能位于同一个国家或地区。
再一次,添加 DISTINCT 关键字会导致查询引擎查看 city 和 country 列中的值组合以评估和删除重复项:
DISTINCT 与 Null 值
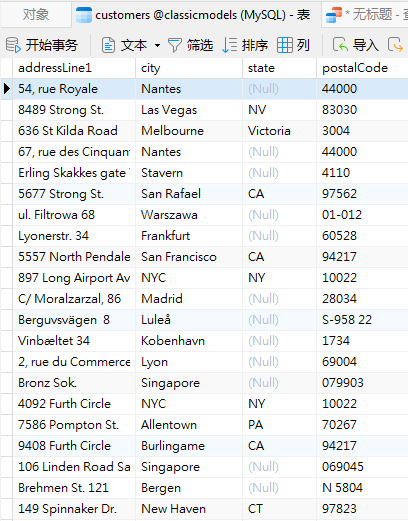
如上所述,DISTINCT 子句将所有 NULL 值视为相同的值,而结果集只会有一个 NULL。我们可以在之前查询的同一个 customers 表中查询这些列来测试一下:
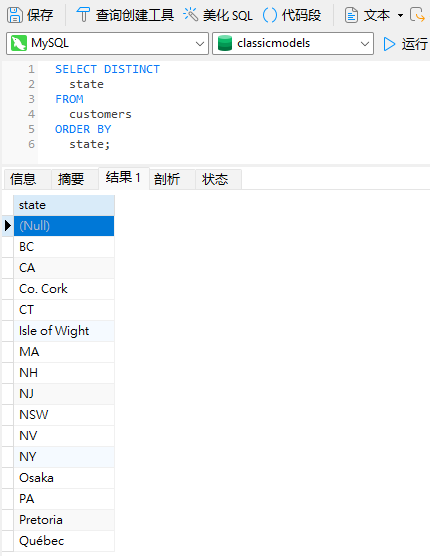
正如预测的那样,添加 DISTINCT 关键字移除了所有 NULL,只剩一个:
关于从关系数据库中选择非重复值的结语
在这篇文章中,我们学习了如何使用 SQL DISTINCT 子句,它从 SELECT 语句的结果集中删除重复项,只留下唯一值。正如我们所见,它可以处理一个或多个列以及 NULL 值。但是,如果你需要在一个或多个列上应用聚合函数,就应该改用 GROUP BY 子句。









