



跟踪销售指标是了解你的业务的一部分,例如销量和找出最佳客户。为此,你可能希望首先获取有关在整个月、季度、年度或其他时间段内购买最多的客户的数据。这些数据能让你分析他们的购买模式并确定趋势。本文将通过将非常有用的 Count() 函数与 GROUP BY 和 HAVING 子句相结合来提供一些示例查询。
基本查询
我们将在 Sakila 示例数据库执行查询。这是一个很好的规范化模式,对 DVD 租赁商店进行建模,包括film、actor、film-actor 关系,以及连接 film、store 和 rental 的中央 inventory 表。因此,它的客户不是购买电影,而是租借电影。尽管如此,选择数据的标准仍然是一样的,即按 customer_id 计算主 rental 表的行数和分组结果的个数。以下是 Navicat Premium 16中的一个基本查询,它将结果限制为总共租借超过 20 部电影的客户:
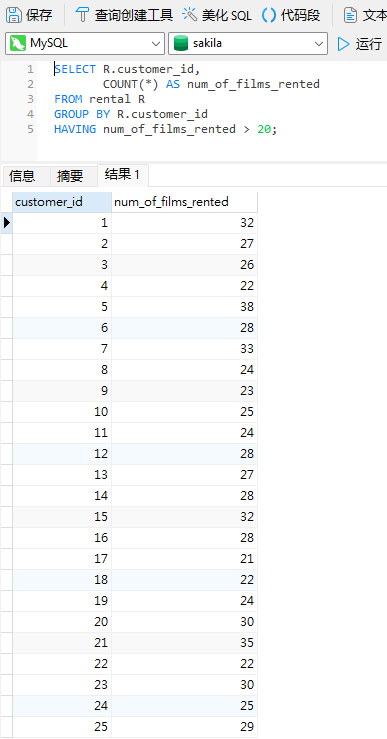
这是按 customer_id 对结果进行排序。稍后,我们将按 num_of_films_rented 排序结果。
获取其他客户详细信息
虽然上述查询足以找到那些租借了许多电影的客户,但它不提供除 ID 之外的任何客户详细信息。若要包含更多客户数据,我们需要加入 customer 表。它应该是用 LEFT JOIN,以便只有租借电影的客户才能加入到主查询中。以下是添加了客户名称的结果:
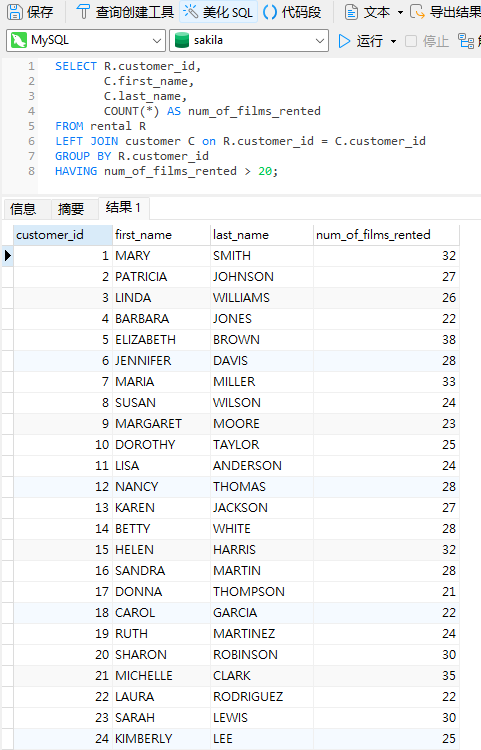
筛选结果
到目前为止,我们已获取非常广泛的数据,包括所有电影和时间段的结果。我们可以针对电影按类别和时间段来获得更具体的信息。为此,我们需要添加更多表。如果你不确定如何将表加入查询,你可以在 Navicat 的对象窗格中选择表,然后运行逆向表到模型...命令:
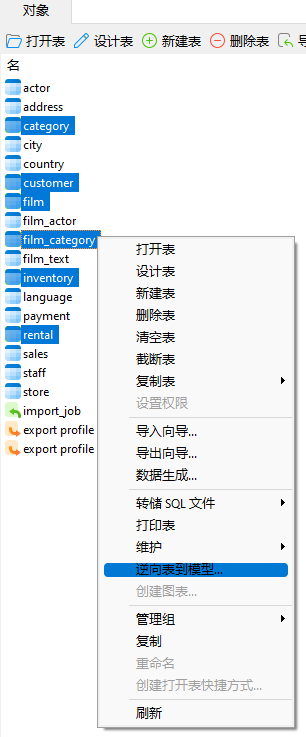
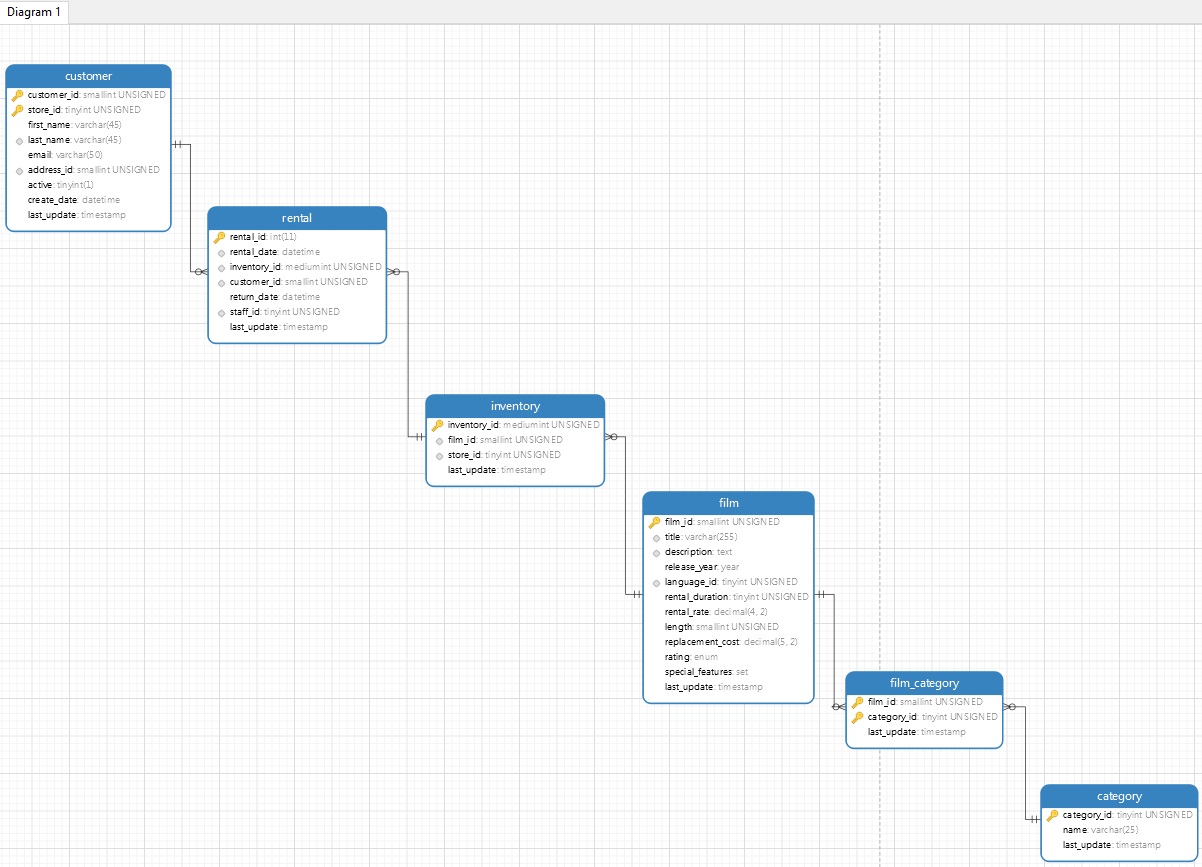
这会将表添加到建模工具中的模式图中,你就可以很容易查看它们的关系:
在修改后的查询中,我们将结果限制为 2005 年租借的喜剧:
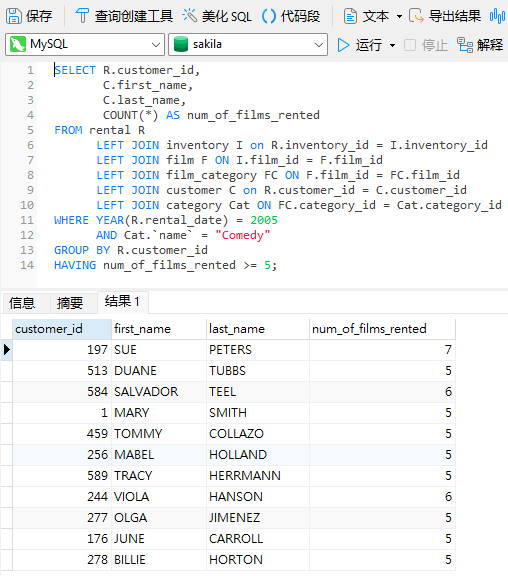
请注意,因为单个类别的租借量较少,最少电影数量已降至 5 或更多。
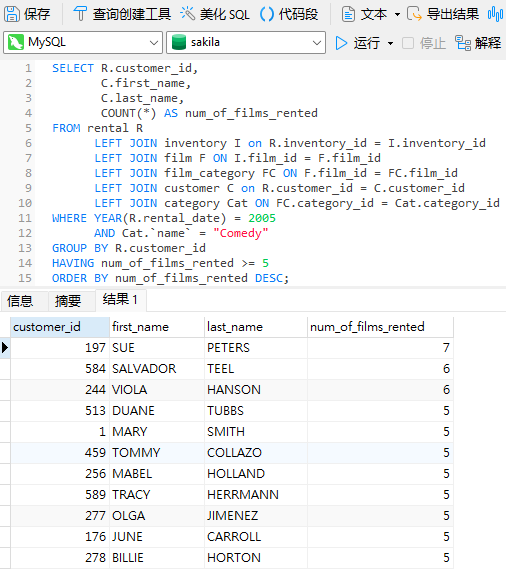
按计数排序
也许你更想按租金计数查看记录。要做到这一点所需要做的就是包含一个 ORDER BY 子句。以下是的最终查询,按 num_of_films_rented 降序(DESC)排序,因此 2005 年租用喜剧最多的客户会在结果的顶部:
总结
在今天的文章中,我们学习了如何将 Count() 函数与 GROUP BY 和 HAVING 子句结合使用,以深入了解客户的消费习惯。正如你想像的那样,可以使用相同的查询结构来发现与产品销售和/或租赁相关的各种趋势和模式。而收集到的见解可以为指导组织决策带来巨大效益。









