



重复组是在整个数据库表中重复的一系列字段/属性。大型和小型组织都面临着一个普遍的问题,这个问题可能会带来多种后果。例如,在不同区域中存在的同一组信息会导致数据冗余和数据不一致。而且,所有这些重复的数据可能会占用大量宝贵的磁盘空间,并需要很长时间进行搜索。在小型组织中,重复组的问题可以解决,但是对于必须管理大量信息的大型组织,重复组可能成为一场噩梦。
在今天的博客中,我们将学习如何在设计时和现有数据库中识别重复组,以及如何修复它们。由于重复组是一种可能影响任何关系数据库的现象,因此我们将使用 Navicat Premium作为我们的数据库开发工具。
重复组的例子
Sakila示例数据库包含许多与虚构视频租赁商店有关的数据库实体。尽管其表已标准化为“第三范式”(3NF),但出于本教程的目的,我们将认为电影表包含有关每部电影中出现的演员的数据。这是该表中的行的示例:
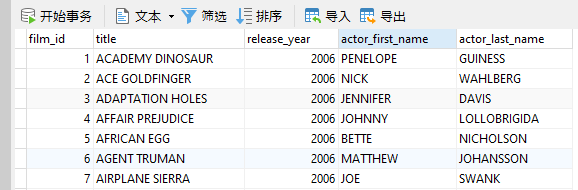
您可以看到每个演员都在表中添加了额外的一行。 更糟糕的是,演员的名字每次出现时都会重复出现。 问题在于演员是与电影分离的独立实体。 因此,他们需要走了。
固定重复组
严格来讲,即使重复组没有违反第一范式(1NF),将数据从非规范化格式(UNF)转换为1NF的过程也会消除重复组。这是执行此操作的步骤:
- 确定重复的数据组。
- 将重复的组字段删除到新表中,并保留主表的副本和剩余的表。
- 原始主键现在将不再是唯一的,因此使用原始主键作为组合键的一部分为关系分配新的主键。
由于我们已经确定了重复组,因此我们重新设计表格,以便省略重复组字段并为其指定自己的表。
Navicat Premium带有内置的 数据模型工具。它可以帮助您直观地设计高质量的概念,逻辑和物理数据模型。从那里,您可以从模型生成数据库结构。 数据建模工具也可以逆向工作,从现有数据库执行逆向工程。其他功能包括从ODBC数据源导入,生成复杂的SQL / DDL以及将模型打印到文件。
这是显示现有的films_and_actors表的模型:
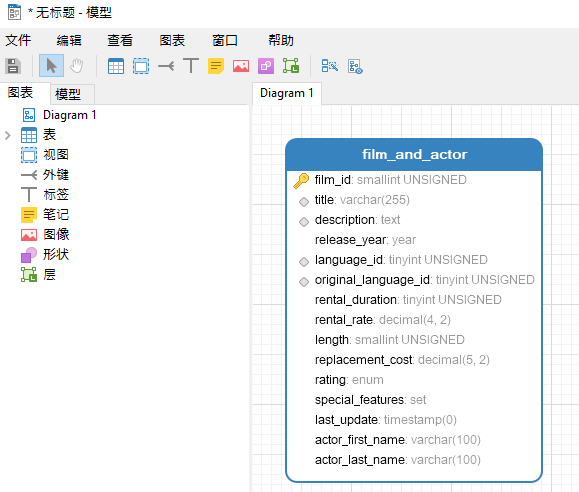
为了将演员与电影分开,我们需要添加一个新表来管理演员属性。 我们还应该给它一个ID PK字段,该字段将链接到原始表中的相同(新FK)字段。.
您还需要重命名表以反映电影表仅包含电影,而演员仅存储演员信息。
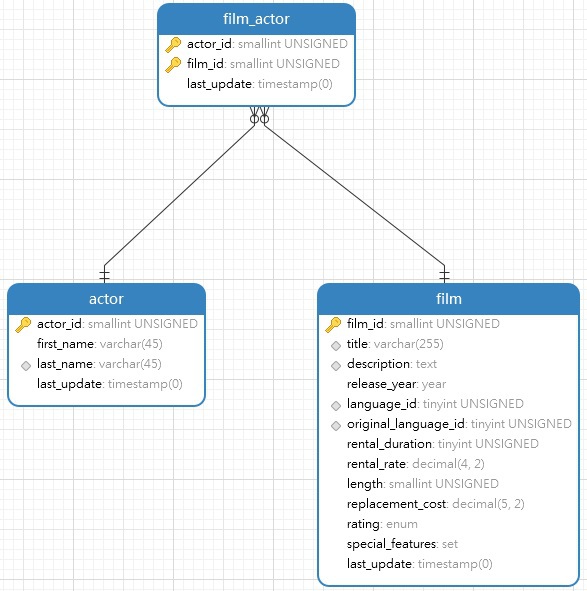
链接电影和演员表
如何将表链接在一起取决于它们之间的特定关系。 在这种情况下,一部电影可能有零个或多个演员,而演员可能出现在一个或多个电影中。 这种多对多的关系将需要一个中介表来链接电影和演员。 它仅包含电影和演员ID。 这是Navicat Modeler中完整的模型:
总论
在今天的博客中,我们学习了如何使用Navicat Premium强大的数据模型工具在设计时和现有数据库中识别重复组,以及如何修复它们。 Navicat Premium添加了100多个增强功能,并包括一些新功能,可为您提供比以往更多的构建,管理和维护数据库的方式!









