



如果你编写 SQL 查询已有一段时间,那么你可能对 WHERE 子句非常熟悉。虽然它对聚合字段没有影响,但有一种方法可以根据聚合值过滤记录,那就是使用 HAVING 子句。本博客将介绍它的工作原理,并提供几个在 SELECT 查询中使用它的示例。
聚合和 Having 子句
聚合通常与分组结合使用。在 SQL 中,可以使用 GROUP BY 子句来实现。通过聚合和分组,我们可以深入了解数据。例如,一家电子商务公司可能希望跟踪特定时间段内的销售情况。
在很多情况下,我们可能不想在整个数据集上应用 GROUP BY 子句。在这种情况下,我们可以使用 GROUP BY 命令和有条件的 HAVING 子句来筛掉不需要的结果。与 WHERE 子句类似,HAVING 指定了一个或多个筛选条件,但针对的是一个组或一个聚合。因此,HAVING 总是放在 WHERE 和 GROUP BY 子句之后,而在(可选的)ORDER BY 子句之前:
SELECT column_list FROM table_name WHERE where_conditions GROUP BY column_list HAVING having_conditions ORDER BY order_expression
一些实例
为了更好地了解 HAVING 如何工作,让我们通过 Sakila 示例数据库 运行几个 SELECT 查询。
我们的第一个查询列出了租片次数最多的人,按降序排序,这样租片次数最多的人就排在最前面。我们将使用 HAVING 子句删除租片次数少于 3 次的客户,以在一定程度上缩短列表:
SELECT
c.customer_id,
c.first_name,
c.last_name,
COUNT(r.rental_id) AS total_rentals
FROM
customer AS c
LEFT JOIN rental AS r ON c.customer_id = r.customer_id
GROUP BY c.customer_id
HAVING total_rentals >= 3
ORDER BY total_rentals DESC;
下面是 Navicat Premium 中的查询及其结果的第一页:
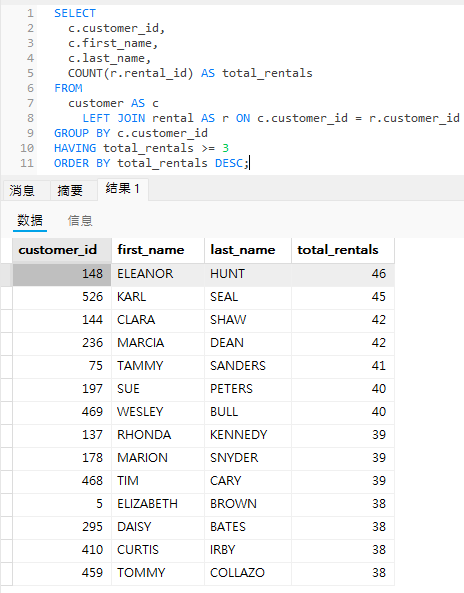
从这些租金数字来看,我们还可以再进一步缩小列表长度!
通过 WHERE 和 HAVING 筛选行
正如 GROUP BY 和 ORDER BY 应用于查询过程的不同阶段一样,WHERE 和 HAVING 也是如此。因此,我们可以在分组和聚合之前和之后加入这两个子句来筛选结果。例如,我们可以添加一个 WHERE 子句,将结果限制在给定年份的上半年:
SELECT
c.customer_id,
c.first_name,
c.last_name,
COUNT(r.rental_id) AS total_rentals
FROM
customer AS c
LEFT JOIN rental AS r ON c.customer_id = r.customer_id
WHERE r.rental_date BETWEEN '2005-01-01' AND '2005-06-30'
GROUP BY c.customer_id
HAVING total_rentals >= 3
ORDER BY total_rentals DESC;
下面是在 Navicat Premium 中运行的上述查询及其结果的第一页:
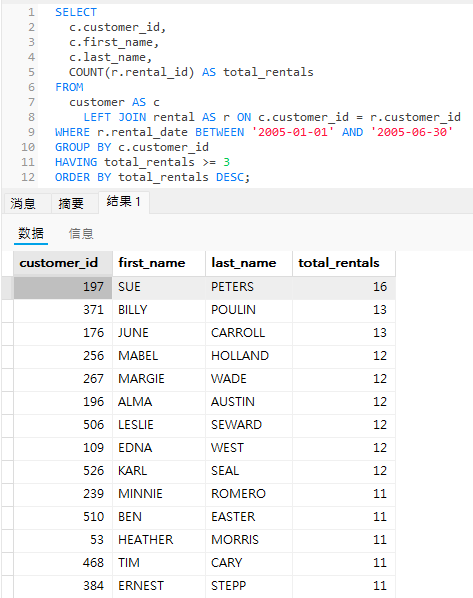
组合多个条件
正如 WHERE 子句使用 AND 和 OR 关键字支持多个条件一样,HAVING 子句也是如此。例如,我们可以将 HAVING 子句修改为类似下面的内容,从而找到租金数字在给定范围内的客户:
HAVING total_rentals >= 3 AND total_rentals <= 10
结语
在今天的博客中,我们学习了如何使用 HAVING 子句筛选分组和聚合字段。
对 Navicat Premium 感兴趣吗?你可以完全免费试用 14 天进行评估!









