在 Navicat for MySQL、PostgreSQL、SQLite、MariaDB 和 Navicat Premium 的非 Essentials 版本中,查询创建工具是一个用于直观地创建和编辑查询的工具。第 4 部分描述了如何在查询中使用原生 SQL 聚合函数以显示列的统计信息。本部分将介绍如何使用查询创建工具根据 HAVING 条件筛选已分组的数据。
关于 Sakila 示例数据库
我们今天将在此处构建的查询将在 Sakila 示例数据库运行。它包含许多以电影业为主题的表,涵盖从演员和电影制片厂到影碟出租店的所有内容。有关下载和安装 Sakila 数据库的说明,请参阅 Generating Reports on MySQL Data(生成 MySQL 数据报表)教程。
使用 HAVING 子句筛选结果组
SQL HAVING 子句是与 GROUP BY 子句结合使用,以根据一个或多个准则限制返回行的组。与在 GROUP BY 子句之前应用的 WHERE 子句相比,HAVING 子句在 GROUP BY 子句聚合行之后再对其应用筛选。
确定有多少名演员同姓
如果我们想知道数据库中有多少名演员与至少两名其他演员同姓,我们可以使用 GROUP BY 子句根据 actors 表的 last_name 字段聚合演员。
我发现无论是使用查询编辑器还是查询创建工具构建查询,最好都是先选择表。
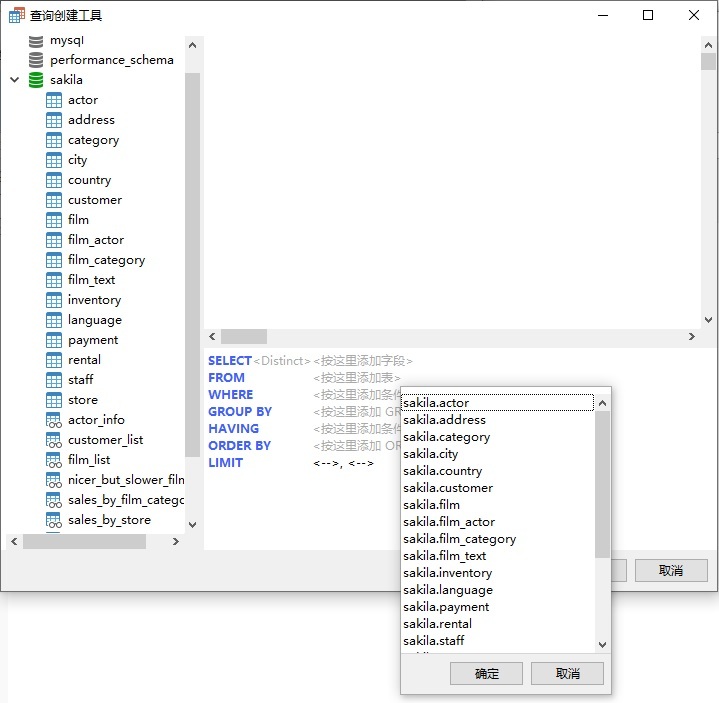
- 考虑到这一点,打开查询创建工具,点击 FROM 关键字旁边的 <按这里添加表> 标签,然后从列表中选择 sakila.actor 表:
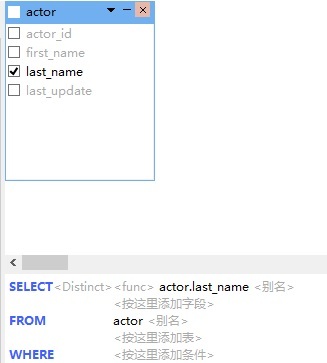
- actor 表及其所有字段会出现在顶部窗格中。我们需要两个字段:last_name 和行数。点击表中 last_name 字段旁边的框:
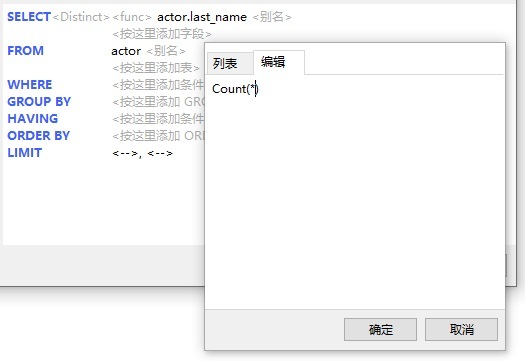
若要将 Count 函数添加到字段列表,请点击 SQL 语句中 actor.last_name 字段下面的 <按这里添加字段> 标签,然后在弹出对话框的“编辑”选项卡中输入“Count(*)”:
- 下一步是添加 GROUP BY 子句。请点击 <按这里添加 GROUP BY> 标签,然后从弹出对话框中选择 actor.last_name 字段。
- 点击“确定”按钮以关闭“查询创建工具”。
这将把以下的 SQL 添加到查询编辑器:
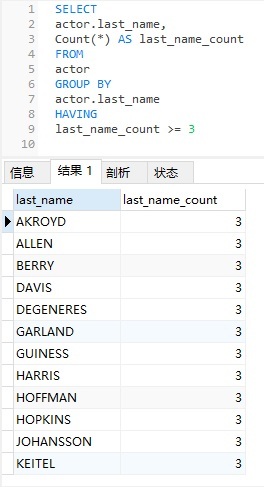
SELECT actor.last_name, Count(*) AS last_name_count FROM actor GROUP BY actor.last_name
以下是上述查询的结果:
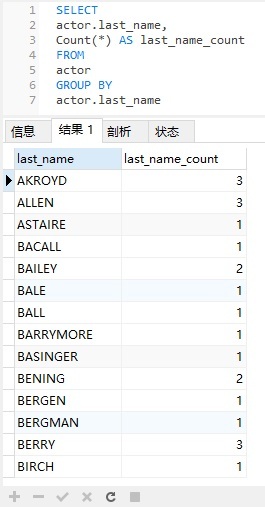
如你所见,结果是按 last_name 进行分组和排序。但它没有将结果限制演员为与至少两个其他演员同姓。为此,我们需要添加HAVING子句。
- 重新打开查询创建工具,然后点击 HAVING 关键字旁边的 <按这里添加条件> 标签。这将插入一个“<-->= <-->”表达式标签。
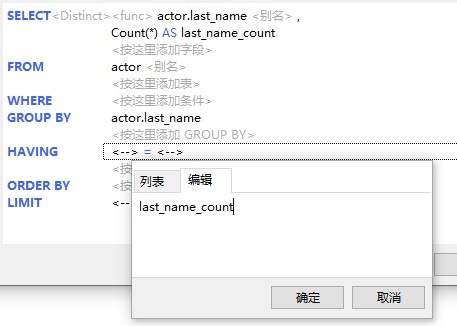
- 点击表达式左侧的“<-->”标签。last_name_count 字段不会出现在字段列表中,因为列表只包含表字段。因此,请在”编辑“选项卡中输入 last_name_count:
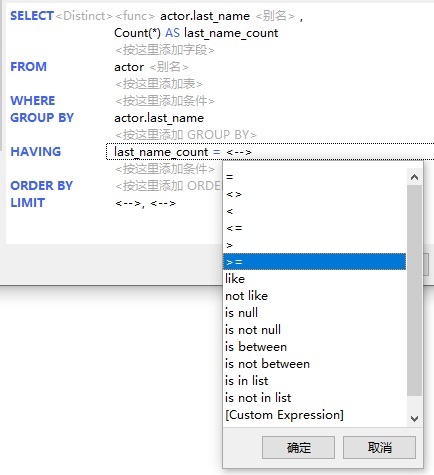
- 接下来,点击等于“=”标签以打开比较运算符列表。从列表中选择“大于或等于”(>=)运算符:
- 最后,点击表达式右侧的“<-->“标签,然后在”编辑“选项卡中输入”3“。
- 点击“确定”按钮以关闭“查询创建工具”。
这将在查询中添加“HAVING last_name_count >= 3”表达式。这次查询只显示在表中姓氏出现三次或更多的演员: