如果你使用了关系数据库(RDBMS)一段时间,几乎可以肯定你已使用了 SQL COUNT() 函数。这样,你无疑已经知道 COUNT() 函数用于返回表中由 WHERE 子句中指定的条件过滤的行数或列数。它灵活的语法和广泛的支持使其成为 SQL 中最通用和有用的函数之一。在今天的文章中,我们将了解它的许多排列并学习如何获得各种计数。
一个函数,多种输入参数变化
作为 ANSI SQL 函数,COUNT() 接受通用 SQL 2003 ANSI 标准语法中的参数。话虽如此,不同的数据库供应商可能有不同的方式来应用 COUNT() 函数。MySQL、PostgreSQL 和 Microsoft SQL Server 均遵循 ANSI SQL 语法:
COUNT(*) COUNT( [ALL|DISTINCT] expression )
同时,DB2 和 Oracle 的语法略有不同:
COUNT ({*|[DISTINCT] expression}) OVER (window_clause)
在本文中,我们将重点介绍 SQL 2003 ANSI 标准语法。以下是所有输入参数的含义:
- ALL:顾名思义,ALL 将 COUNT 应用于所有值,以便它返回非 NULL 值的数量。
- DISTINCT:忽略重复的值,以便 COUNT 返回唯一的非 NULL 值的数量。
- Expression:由以下部分组成的表达式:
- 一个常量、变量、标量函数
- 一个列名
- SQL 查询的一部分,该查询将值与其他值进行比较
- *:计算目标表中的所有行,无论它们是否包含 NULL。
实际示例
为了对各种语法排列及其对 COUNT 输出的影响进行采样,让我们将 COUNT() 函数应用于以下雇员表,如 Navicat for MySQL 所示:
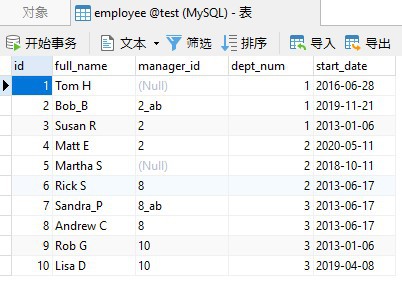
现在,这个查询计算了几项数据的数目:
- 雇员总数
- 经理人数
- 非经理人数
- 部门数

如上面的查询所示,获得不同的计数完全与如何使用 COUNT() 函数有关。关于何时使用特定的列名而不是星号,请注意前者将不计算 Null,而后者通常将计算 Null,因为它包括所有列。至于何时使用 DISTINCT,请考虑将其用于具有重复值的列,这通常包含定义为非唯一和/或非主键的列。
总结
SQL COUNT () 函数灵活的语法和广泛的支持使其成为 SQL 中最通用和有用的函数之一。说到语法,如果你很难记住 COUNT() 函数的语法,可以让 Navicat 提醒你!它的自动完成建议列表不仅提供表名和列名,还提供存储过程和函数,包括 COUNT()。你会发现它不只一个版本,而是有两个版本:一个是简单用法,另一个是更复杂的用法: