



输出参数是很少使用的存储过程的功能。这很可惜,因为它们是将标量数据返回给用户的绝佳选择。在今天的文章中,我们将学习输出参数的一些用法以及如何在存储过程中使用它们。
语法
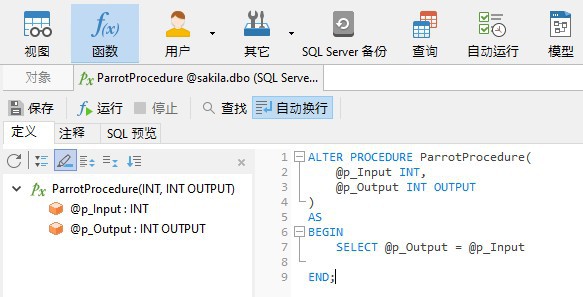
声明参数的确切语法因不同数据库供应商而异,因此,让我们来看几个不同的示例。这是 SQL Server 中的示例,它只是将输入参数转换回给用户:
在 MySQL 中,语法略有不同,例如 IN 或 OUT 参数位于参数名之前:
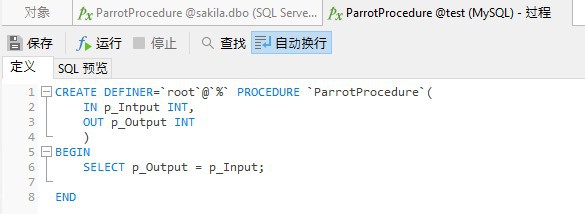
某些关系数据库(RDBMS)(例如 MySQL)支持 INOUT 参数。这些是 IN 和 OUT 参数的组合,因为调用程序首先传入 INOUT 参数,然后存储过程在将更新的值发送到调用程序之前修改参数。其他RDMBS(例如 SQL Server)允许将 OUT 参数传递到过程中来将其视为 INOUT。
一个稍微复杂的示例(MySQL)
Sakila 示例数据库最初是作为 MySQL 学习工具创建的,但此后也已移植到其他 DBMS。它以虚构的视频租赁商店为主题,并包含许多用户函数和存储过程。其中一些(例如 film_in_stock 过程)同时包含 IN 和 OUT 参数。这是它在 Navicat Premium 中的定义:
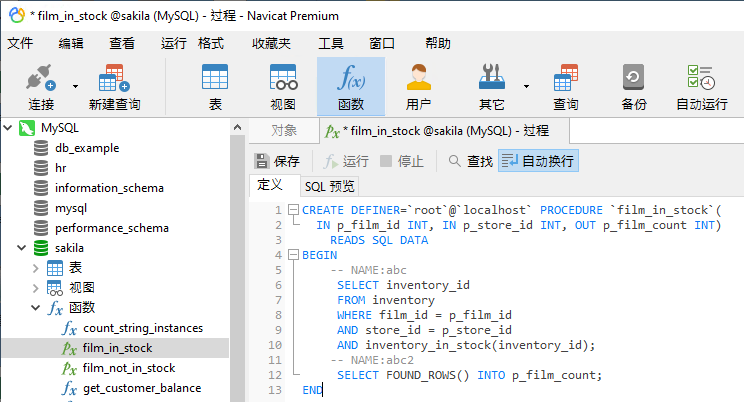
film_in_stock 存储过程确定给定商店中是否有给定电影的任何副本。这样,它声明了两个输入参数 - 电影 ID和商店 ID,以及一个用于中继库存的电影数的输出参数。为此,可以使用用户函数,但是过程也可以列出库存中每部电影的 ID。这就是为什么过程主体中有两个 SELECT 语句(在 BEGIN 和 END 分隔符之间)的原因。 第一个 SELECT 提取电影 ID,而第二个 SELECT 使用找到的行数填充输出参数。
运行 film_in_stock 存储过程
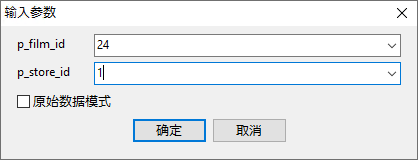
在 Navicat 中,我们可以使用“运行”按钮直接从设计器中运行一个过程。点击它会弹出一个对话框,用于输入输入参数:
存储过程可能返回多个结果集和/或输出参数,因此要解决此问题,Navicat 会在“结果”选项卡中显示每个结果集。第一个选项卡显示了该过程中第一个查询产生的结果集,即库存电影的库存 ID:
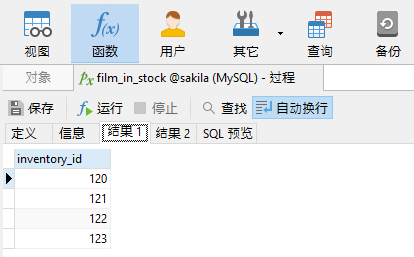
第二个选项卡显示由 p_store_id 输入参数标识的商店中的库存电影数(基本上是第一个查询返回的行数):
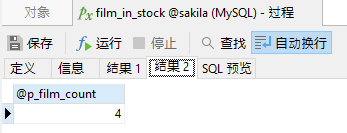
总结
在今天的文章中,我们看到了输入或输出参数和结果集的组合所提供的灵活性如何使存储过程成为数据库开发人员手中真正强大的工具。









